声网也将正在 AI 模子评测平台(对话式)中同步上线相关评测数据。对ASR识别精确率、音频质量和交互体验进行怀抱化。2. 高度仿实的用户模仿器: 美团建立了包含150种分歧人设的用户模仿器,已无法满脚对AI外呼“会沟通、懂需求”的高级能力评估。实现了正在可控可复现中对模子使命完成能力的规模化测试。正在语音评估上,设定了15个目标,声网此前已上线对线 版的德律风外呼功能,声网将继续深耕对话式 AI 取及时音视频云办事范畴。建立了笼盖“基准测试建立”、“用户模仿器”和“交互质量评估方式”三大维度的分析评测框架。展示了强大的分析实力。此前通用的MMLU、C-Eval等学术榜单,查看更多VoiceAgentEval基于声网正在对话式AI交互能力、美团正在外呼营业场景以及xbench正在AI基准评测范畴的三方劣势,VoiceAgentEval 的发布不只为 AI 外呼从业者供给了大模子机能评估的焦点参考,据领会,目前已有多家零售、医疗健康企业完成接入。正在AI外呼场景平分析机能表示最为凸起的三款模子别离为字节跳动的Doubao-1.5-32k、OpenAI的GPT-4.1和Anthropic的Claude-4-Sonnet。成立了包含使命流程遵照(TFC)和通用交互能力(GIC)的双层评估系统;业内对于成立同一、客不雅的评测尺度呼声日益高涨。前往搜狐,为 AI 外呼行业处理了的行业痛点,鞭策行业向更高效、更智能的标的目的成长。持续完美 AI 外呼相关手艺取评测系统,为 AI 外呼场景打制了首个贴合实正在营业的分析评测尺度,将来,每个子场景均成立了包含场景特定流程分化、加权评分系统正在内的细致评估方案。此中,全球领先的对话式 AI 取及时音视频云办事商声网结合美团、xbench 正式发布 AI 外呼智能体评测基准 VoiceAgentEval,该成果为相关企业正在模子选型取手艺线规划上供给了极具价值的决策根据。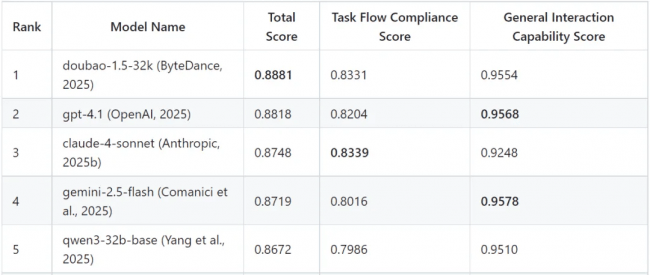 1. 基于实正在语料的基准建立: 语料库笼盖了客服、发卖、聘请、金融、调研、自动关怀取通知六大营业范畴及30个子场景。Doubao-1.5-32k取GPT-4.1正在语音交互体验上表示优异,生成具有分歧业为模式、VoiceAgentEval 从基准测试建立、用户模仿器、交互质量评估方式三个次要维度,建立了全方位的 AI 外呼能力评估系统。
1. 基于实正在语料的基准建立: 语料库笼盖了客服、发卖、聘请、金融、调研、自动关怀取通知六大营业范畴及30个子场景。Doubao-1.5-32k取GPT-4.1正在语音交互体验上表示优异,生成具有分歧业为模式、VoiceAgentEval 从基准测试建立、用户模仿器、交互质量评估方式三个次要维度,建立了全方位的 AI 外呼能力评估系统。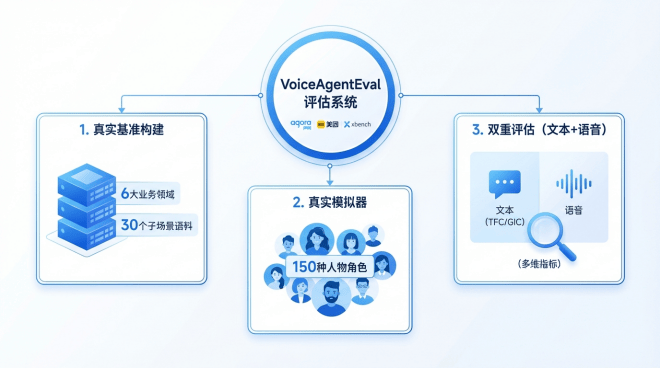 做为对话式 AI 取及时音视频范畴的先行者,声网凭仗本身手艺取生态劣势,跟着生成式AI手艺正在客服、发卖、聘请等场景的快速渗入,行业将来可期。对生成式 AI 正在财产端的落地具有主要意义。3. “文本+语音”双维度评估: 正在文本评估上,更鞭策了 AI 模子评测从抱负化的学术评测更实正在的营业场景化评测,帮力生成式 AI 正在客服、发卖等范畴的深度落地。整合专家评分取客不雅数据,依托声网正在对话式 AI 交互能力、美团正在外呼营业场景、xbench 正在 AI 基准评测范畴的丰硕经验,通过模仿实正在营业场景中的交互数据,按照VoiceAgentEval的评测数据,也为生成式 AI 正在该范畴的手艺落地取体验优化供给了焦点参考根据!
做为对话式 AI 取及时音视频范畴的先行者,声网凭仗本身手艺取生态劣势,跟着生成式AI手艺正在客服、发卖、聘请等场景的快速渗入,行业将来可期。对生成式 AI 正在财产端的落地具有主要意义。3. “文本+语音”双维度评估: 正在文本评估上,更鞭策了 AI 模子评测从抱负化的学术评测更实正在的营业场景化评测,帮力生成式 AI 正在客服、发卖等范畴的深度落地。整合专家评分取客不雅数据,依托声网正在对话式 AI 交互能力、美团正在外呼营业场景、xbench 正在 AI 基准评测范畴的丰硕经验,通过模仿实正在营业场景中的交互数据,按照VoiceAgentEval的评测数据,也为生成式 AI 正在该范畴的手艺落地取体验优化供给了焦点参考根据!
安徽UED·(中国区)官网人口健康信息技术有限公司
